How to Read Fixed Width File in R
Gentoo penguins in Antarctica, walking forth a "penguin highway", a path that joins the sea and their nesting area on a rocky outcrop.
Who doesn't like penguins? They accept a quirky charm, and are an amazing demonstration of the power of evolution: they wing just but underwater, and are adapted to thrive in some of the harshest climates on Earth.
The {palmerpenguins} R package contains data collected at the Palmer Station on Anvers Island in the Antarctic. The data is measurement data about three unlike species of penguins, from iii smaller islands in the expanse. You lot can find out more most the information in the package, too every bit some examples of exploring and analyzing the information using R, hither: https://allisonhorst.github.io/palmerpenguins/
Fixed-width files
This exercise in data import uses a modification of the data found in the {palmerpenguins} bundle—I have converted the data file to a fixed-width format. 1
This type of plain text file isn't used as much as other types, but you may come beyond them in your information science journey.
1 of the attributes of stock-still-width files is that there are no delimiters equally there are in file types such as CSV (Comma-Separated Value) and TSV (Tab-Separated Value) files. Instead, variables are assigned to specific columns in the file's rows. This means that for very large files, reading the data can be accomplished more efficiently because there is no need to search for commas or other delimiters every bit every row is read. In addition, the claiming of embedded delimiters is eliminated, since there are none at all.
When computer memory was far more expensive than it is at present, there was a cost incentive to create files that minimized the number of characters, including white space. This incentive was compounded when data was stored on punch cards, which had a physical constraint of an 80 graphic symbol width; in that scenario, methods to eliminate whatsoever superfluous characters were sought. 2
Here in 2020, cheaper storage and efficient compression methods have meant that CSV files with unfixed variable lengths are more than common, but in some big information applications, stock-still-width files are still used.
Fixed-width penguins
The first x rows of the penguins_fwf.txt file wait like this:
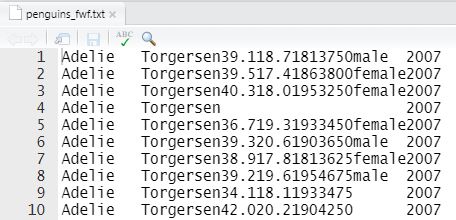
penguins_fwf.txt
Notation that the first row does non contain the variable names, but the first record—the observed characteristics of the first penguin in our dataset. This type of structure, with the variable names stored separately, is common in stock-still-width files.
As well note that white space is at a minimum. For example, in the commencement records there are ii blank spaces after the give-and-take "male" because "female" has two more letters (as is shown in the second record); the variable has to be wide enough to accommodate the value with the about characters. In data files where the creators are really serious nigh saving space, a variable similar sex would exist coded using a single digit (mayhap 1 = "female" and ii = "male", only be careful! 3), rather than the six characters required to spell out the words.
In the penguins_fwf.txt file in that location are 8 different variables, described in the tabular array below:
| Variable | Width | Beginning position | Finish position |
|---|---|---|---|
| species | ix | i | nine |
| island | 9 | x | 18 |
| bill_length_mm | 4 | 19 | 22 |
| bill_depth_mm | iv | 23 | 26 |
| flipper_length_mm | iii | 27 | 29 |
| body_mass_g | iv | 30 | 33 |
| sex | vi | 34 | 39 |
| year | 4 | xl | 43 |
This sort of detailed table is a common component in a data lexicon for a fixed-width file, and is an important element in programming the code to parse the file. In improver to providing vital data to the data user, developing this table as well provides a double-bank check for the information preparer on the accuracy of the location specifications.
Importing stock-still-width files with {readr}
The tidyverse package {readr}, part of the tidyverse family of R packages, provides a range of functions that brand reading these files efficient.
# load the {readr} package library(readr) The widths and variable names can be added as lists to the fwf_widths argument:
read_fwf("penguins_fwf.txt", fwf_widths(widths = c(9, 9, 4, 4, 3, 4, 6, 4), col_names = c("species", "isle", "bill_length_mm", "bill_depth_mm", "flipper_length_mm", "body_mass_g", "sex", "yr"))) ## # A tibble: 344 ten 8 ## species island bill_length_mm bill_depth_mm flipper_length_~ body_mass_g ## <chr> <chr> <dbl> <dbl> <dbl> <dbl> ## 1 Adelie Torge~ 39.1 18.seven 181 3750 ## ii Adelie Torge~ 39.5 17.four 186 3800 ## iii Adelie Torge~ 40.3 18 195 3250 ## four Adelie Torge~ NA NA NA NA ## 5 Adelie Torge~ 36.7 19.3 193 3450 ## half-dozen Adelie Torge~ 39.iii 20.half-dozen 190 3650 ## 7 Adelie Torge~ 38.9 17.8 181 3625 ## 8 Adelie Torge~ 39.ii 19.6 195 4675 ## 9 Adelie Torge~ 34.ane eighteen.1 193 3475 ## 10 Adelie Torge~ 42 20.2 190 4250 ## # ... with 334 more than rows, and 2 more variables: sex <chr>, yr <dbl> A second option is to provide two lists of locations using fwf_positions(), the first with the start positions, and the second with the end positions. The commencement variable "species" starts at position one and ends at position 9, and the second variable "island" starts at 10 and ends at 18, and so on.
read_fwf("penguins_fwf.txt", fwf_positions(start = c(1, ten, xix, 23, 27, 30, 34, 40), cease = c(9, 18, 22, 26, 29, 33, 39, 43), col_names = c("species", "island", "bill_length_mm", "bill_depth_mm", "flipper_length_mm", "body_mass_g", "sex", "year"))) ## # A tibble: 344 x 8 ## species island bill_length_mm bill_depth_mm flipper_length_~ body_mass_g ## <chr> <chr> <dbl> <dbl> <dbl> <dbl> ## 1 Adelie Torge~ 39.1 xviii.7 181 3750 ## ii Adelie Torge~ 39.5 17.4 186 3800 ## iii Adelie Torge~ 40.three xviii 195 3250 ## 4 Adelie Torge~ NA NA NA NA ## 5 Adelie Torge~ 36.7 xix.3 193 3450 ## 6 Adelie Torge~ 39.3 20.six 190 3650 ## seven Adelie Torge~ 38.9 17.8 181 3625 ## eight Adelie Torge~ 39.2 19.vi 195 4675 ## ix Adelie Torge~ 34.i eighteen.1 193 3475 ## 10 Adelie Torge~ 42 xx.2 190 4250 ## # ... with 334 more than rows, and 2 more variables: sexual activity <chr>, twelvemonth <dbl> The third selection, fwf_cols, is a syntactic variation on the second approach, with the same values but in a different order. This time, all of the relevant data about each variable is aggregated, with the name followed past the start and end locations.
read_fwf("penguins_fwf.txt", fwf_cols(species = c(ane, 9), island = c(10, 18), bill_length_mm = c(xix, 22), bill_depth_mm = c(23, 26), flipper_length_mm = c(27, 29), body_mass_g = c(30, 33), sex = c(34, 39), year = c(twoscore, 43) )) ## # A tibble: 344 x 8 ## species isle bill_length_mm bill_depth_mm flipper_length_~ body_mass_g ## <chr> <chr> <dbl> <dbl> <dbl> <dbl> ## i Adelie Torge~ 39.ane 18.7 181 3750 ## 2 Adelie Torge~ 39.5 17.4 186 3800 ## iii Adelie Torge~ 40.3 18 195 3250 ## iv Adelie Torge~ NA NA NA NA ## five Adelie Torge~ 36.7 nineteen.3 193 3450 ## 6 Adelie Torge~ 39.3 twenty.6 190 3650 ## 7 Adelie Torge~ 38.9 17.8 181 3625 ## 8 Adelie Torge~ 39.2 xix.six 195 4675 ## 9 Adelie Torge~ 34.1 xviii.i 193 3475 ## 10 Adelie Torge~ 42 20.2 190 4250 ## # ... with 334 more than rows, and 2 more variables: sex <chr>, yr <dbl> And finally, {readr} provides a fourth way to specify the variables in a fixed-width file. Similar to the previous example, this variation has the proper name and the width values specified together.
# read read_fwf("penguins_fwf.txt", fwf_cols( species = nine, island = 9, bill_length_mm = iv, bill_depth_mm = four, flipper_length_mm = iii, body_mass_g = 4, sexual practice = vi, year = iv ) ) ## # A tibble: 344 x 8 ## species island bill_length_mm bill_depth_mm flipper_length_~ body_mass_g ## <chr> <chr> <dbl> <dbl> <dbl> <dbl> ## 1 Adelie Torge~ 39.one eighteen.7 181 3750 ## 2 Adelie Torge~ 39.5 17.iv 186 3800 ## 3 Adelie Torge~ 40.three eighteen 195 3250 ## 4 Adelie Torge~ NA NA NA NA ## 5 Adelie Torge~ 36.7 19.three 193 3450 ## vi Adelie Torge~ 39.3 20.6 190 3650 ## 7 Adelie Torge~ 38.nine 17.8 181 3625 ## 8 Adelie Torge~ 39.2 19.half-dozen 195 4675 ## nine Adelie Torge~ 34.i xviii.1 193 3475 ## 10 Adelie Torge~ 42 twenty.2 190 4250 ## # ... with 334 more than rows, and two more variables: sex activity <chr>, yr <dbl> As with all of the functions in {readr}, nosotros accept the ability to specify the blazon of variables we want in our information in the script the reads the file. Heed the wisdom of Jenny Bryan:
My main import communication: use the arguments of your import function to become as far equally you can, equally fast as possible. Novice code ofttimes has a great bargain of unnecessary post import fussing effectually. Read the docs for the import functions and have maximum advantage of the arguments to command the import. 4
Here'south the docs for the {readr} functions to "Read a fixed width file into a tibble": https://readr.tidyverse.org/reference/read_fwf.html
An instance: starting with the fwf_cols choice we saw above, the code below uses col_types to specify "sex" as a gene, and "yr" as an integer.
For this final version, I've used the kable() function from the {knitr} package to render the first 10 rows from the table.
# with column specification penguins <- read_fwf("penguins_fwf.txt", fwf_cols( species = nine, island = nine, bill_length_mm = 4, bill_depth_mm = 4, flipper_length_mm = 3, body_mass_g = 4, sex = 6, year = 4 ), col_types = cols(sex = col_factor(), year = col_integer()) ) knitr::kable(head(penguins, n = x), format = "html") | species | island | bill_length_mm | bill_depth_mm | flipper_length_mm | body_mass_g | sex activity | year |
|---|---|---|---|---|---|---|---|
| Adelie | Torgersen | 39.1 | 18.seven | 181 | 3750 | male | 2007 |
| Adelie | Torgersen | 39.five | 17.iv | 186 | 3800 | female | 2007 |
| Adelie | Torgersen | 40.3 | eighteen.0 | 195 | 3250 | female | 2007 |
| Adelie | Torgersen | NA | NA | NA | NA | NA | 2007 |
| Adelie | Torgersen | 36.vii | nineteen.3 | 193 | 3450 | female person | 2007 |
| Adelie | Torgersen | 39.three | 20.6 | 190 | 3650 | male | 2007 |
| Adelie | Torgersen | 38.ix | 17.8 | 181 | 3625 | female person | 2007 |
| Adelie | Torgersen | 39.two | xix.half-dozen | 195 | 4675 | male | 2007 |
| Adelie | Torgersen | 34.1 | 18.ane | 193 | 3475 | NA | 2007 |
| Adelie | Torgersen | 42.0 | 20.2 | 190 | 4250 | NA | 2007 |
-30-
Source: https://martinmonkman.com/post/2020-09-15_penguins/
0 Response to "How to Read Fixed Width File in R"
Post a Comment